
Hyperstate AI
Rompimos el monolito GPU. Menos latencia, menos factura, deploys que no necesitan sala de crisis.
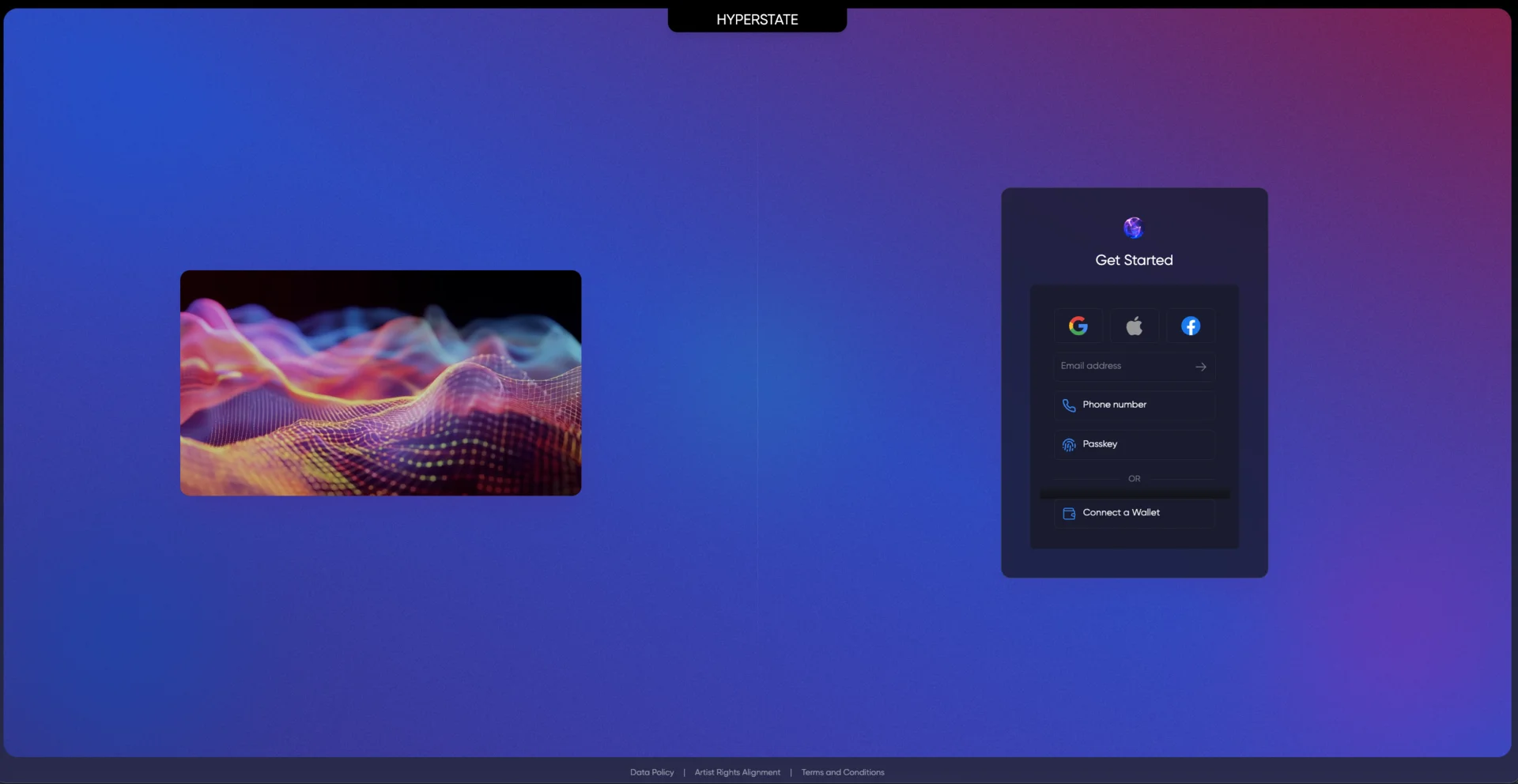
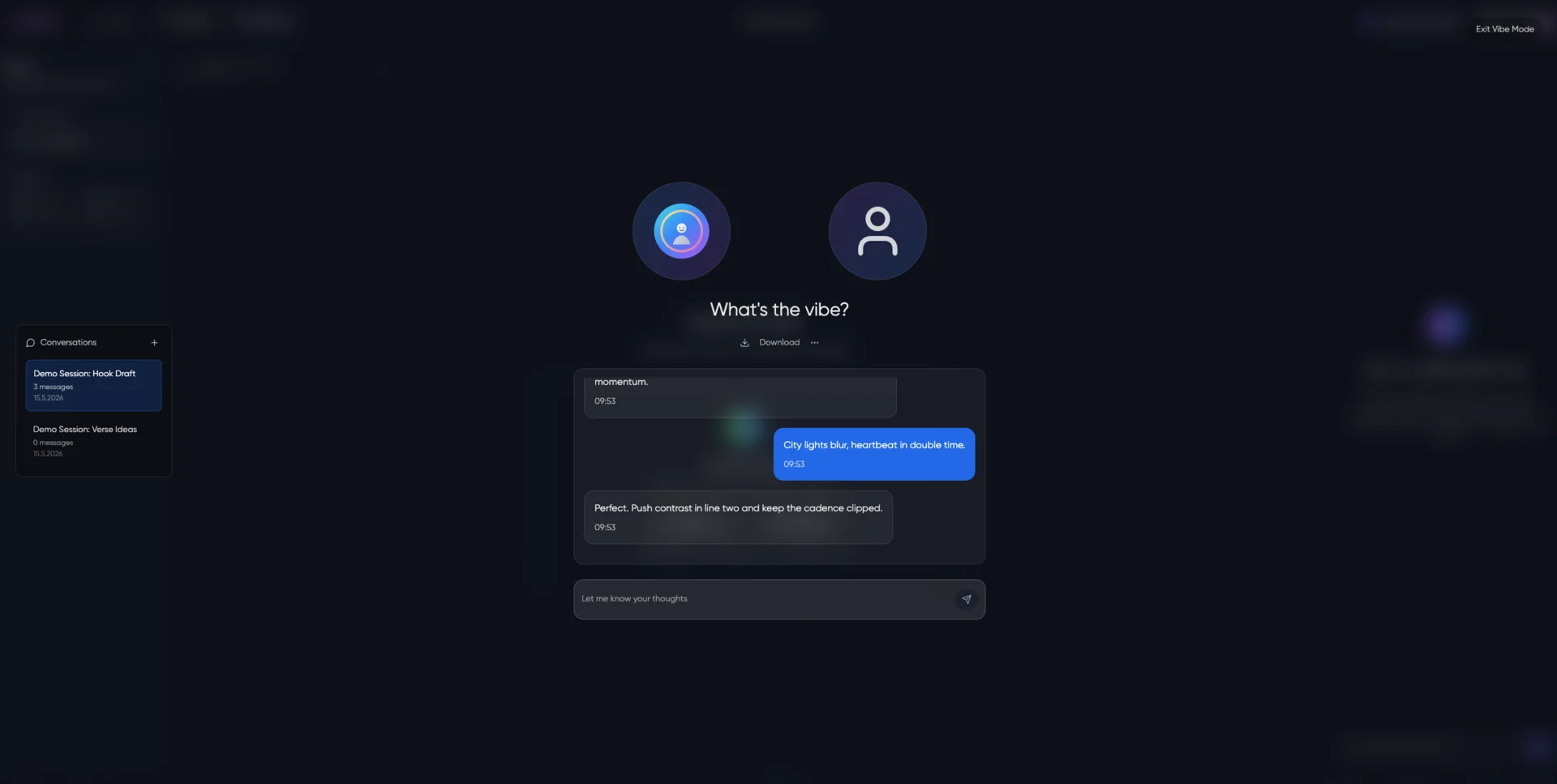
Hyperstate AI operaba una plataforma de producción musical asistida por IA. Los creadores subían audio y trabajaban con un asistente estilo productor (la persona de Louis Bell) que conservaba el contexto completo entre sesiones. La startup se quedó sin financiación tras el lanzamiento.
Resumen
Hyperstate AI operaba una plataforma de producción musical asistida por IA. Los creadores subían audio y trabajaban con un asistente estilo productor (la persona de Louis Bell) que conservaba el contexto completo entre sesiones. La startup se quedó sin financiación tras el lanzamiento.
El Reto
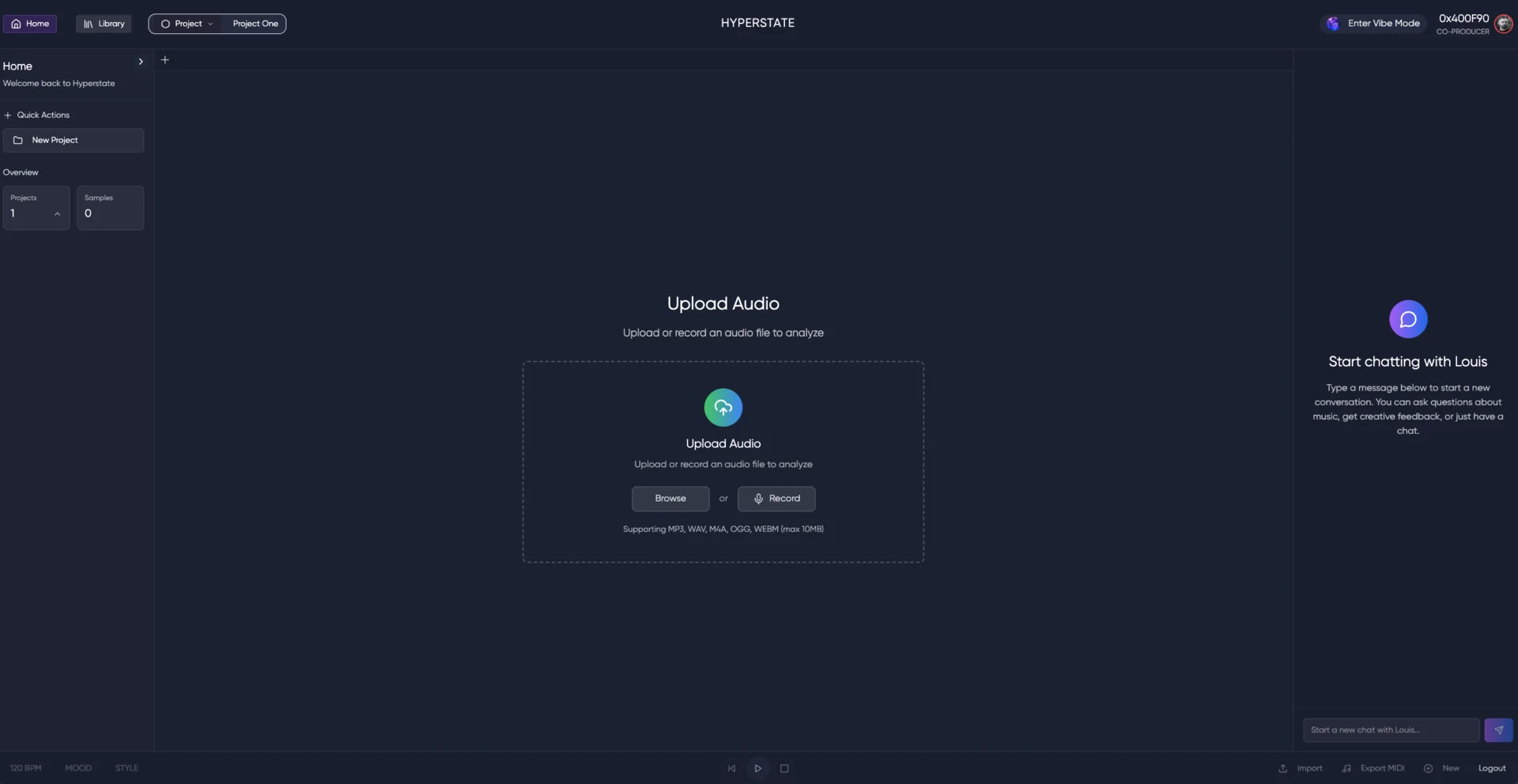
Un único servidor GPU manejaba procesamiento de audio, letras, transcripción, generación MIDI y el agente productor. Deploys manuales. La factura de cómputo crecía más rápido que el uso. La arquitectura aguantó una demo, pero no el lanzamiento – sin escalado horizontal, sin aislamiento de fallos, un mal deploy tiraba todo el producto.
Un solo servidor para todo no iba a sobrevivir al lanzamiento.
Procesamiento de audio, letras, transcripción, generación – todo apilado en una caja GPU, deployado a mano. Aguantó la demo y se cayó bajo carga real. Lo dividimos en servicios enfocados con fronteras de responsabilidad limpias, dockerizamos cada componente y reemplazamos las librerías internas más pesadas por alternativas ligeras y escalables hospedadas. Misma superficie de producto, una fracción de la factura de cómputo, deploys que nadie tiene que vigilar.
Lo que hicimos
Llevamos las integraciones pesadas de GPU del setup monolítico de un solo servidor a un backend distribuido orientado a microservicios con responsabilidades claramente separadas – agentes, procesamiento de audio y servicios de generación, cada uno con su propio perfil de escalado. Modernizamos el stack de despliegue de deploys manuales a una infraestructura dockerizada y orquestada en cada componente. Migramos las librerías locales, auto-gestionadas y computacionalmente pesadas de audio, letras y transcripción a alternativas ligeras y escalables – bajando latencia y factura de cómputo en el mismo movimiento. Encima: API REST en Django, auth JWT vinculada a thirdweb, gestión de proyectos y samples, flujos de generación MIDI, grafo de conocimiento Neo4j, PostgreSQL. Misma superficie de producto, infraestructura que sostiene el crecimiento en vez de pelear con él.
Resultados
Lo que aprendimos
El trabajo ML pesado no pertenece a tu ruta de petición web. En cuanto audio, letras y transcripción cargan cada uno un modelo en la misma caja, cualquier pico de carga se lleva todo el producto por delante. La ganancia es infraestructura aburrida: servicios separados para perfiles de cómputo separados, deploys orquestados, alternativas hospedadas para las librerías que no tienes por qué mantener.

¿Quieres resultados como estos?
Cuéntanos qué estás construyendo. Te diremos si somos el equipo adecuado.
Agendar llamada