
Hyperstate AI
GPU-Monolith aufgebrochen. Niedrigere Latenz, niedrigere Rechnung, Deployments ohne Krisenstab.
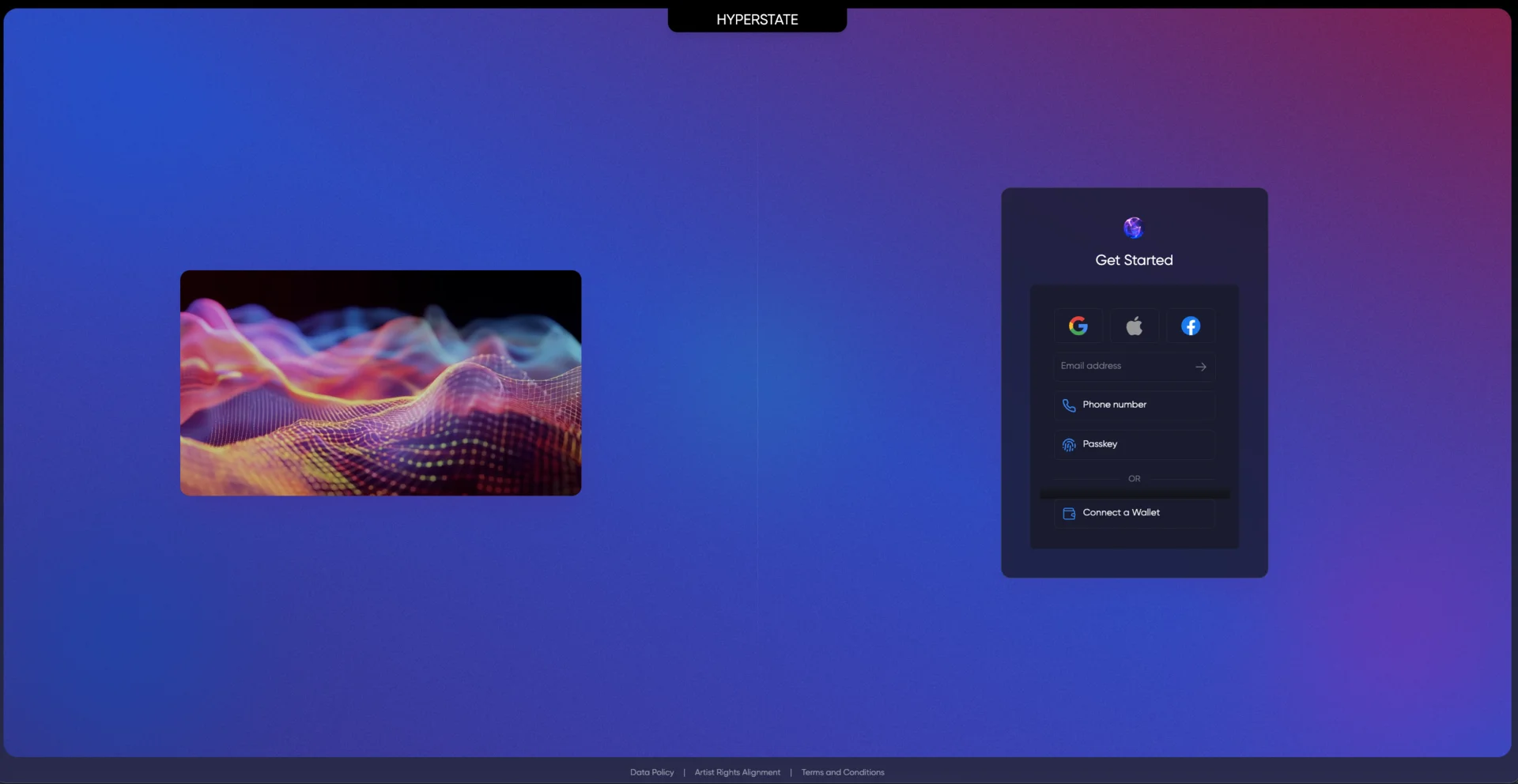
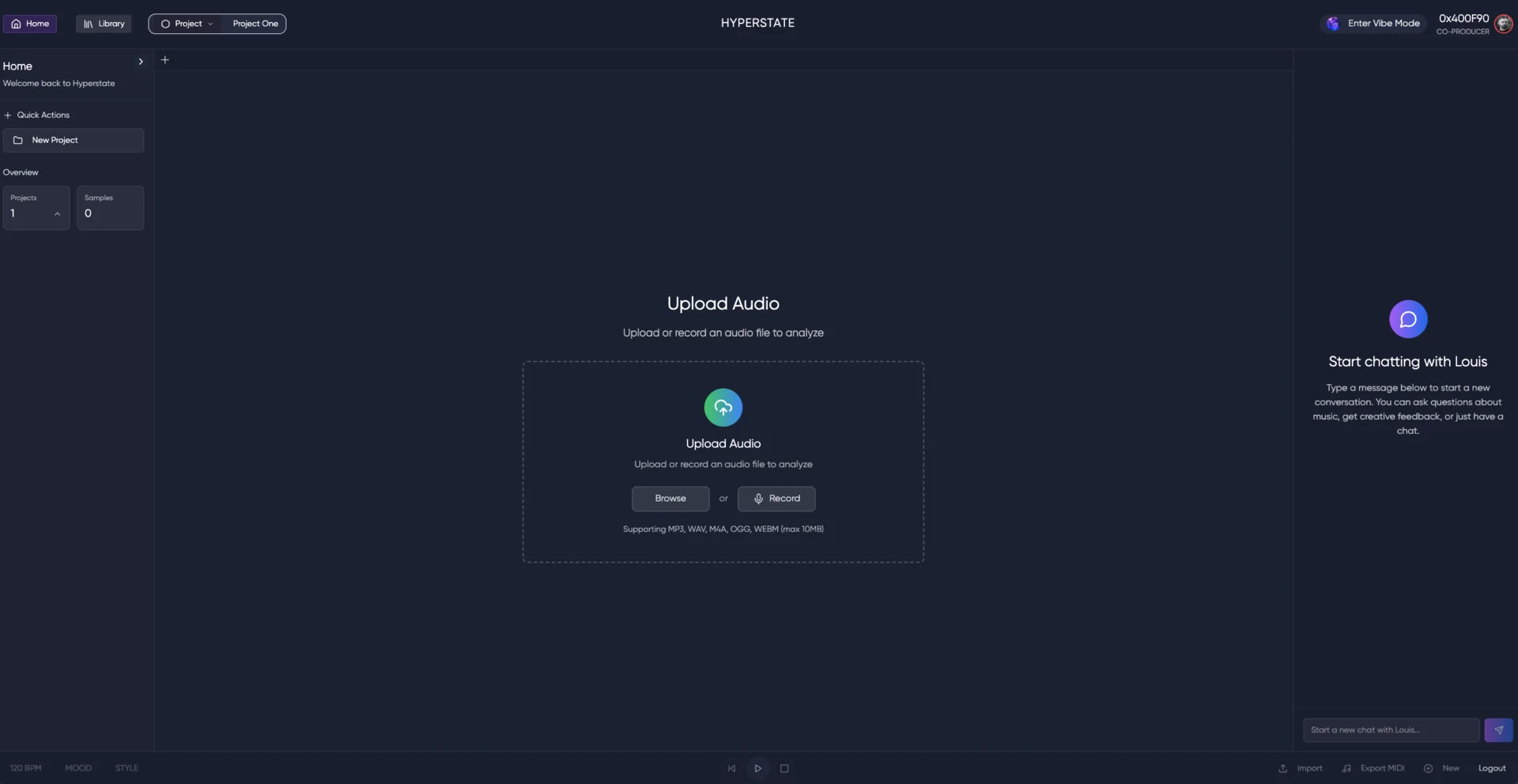
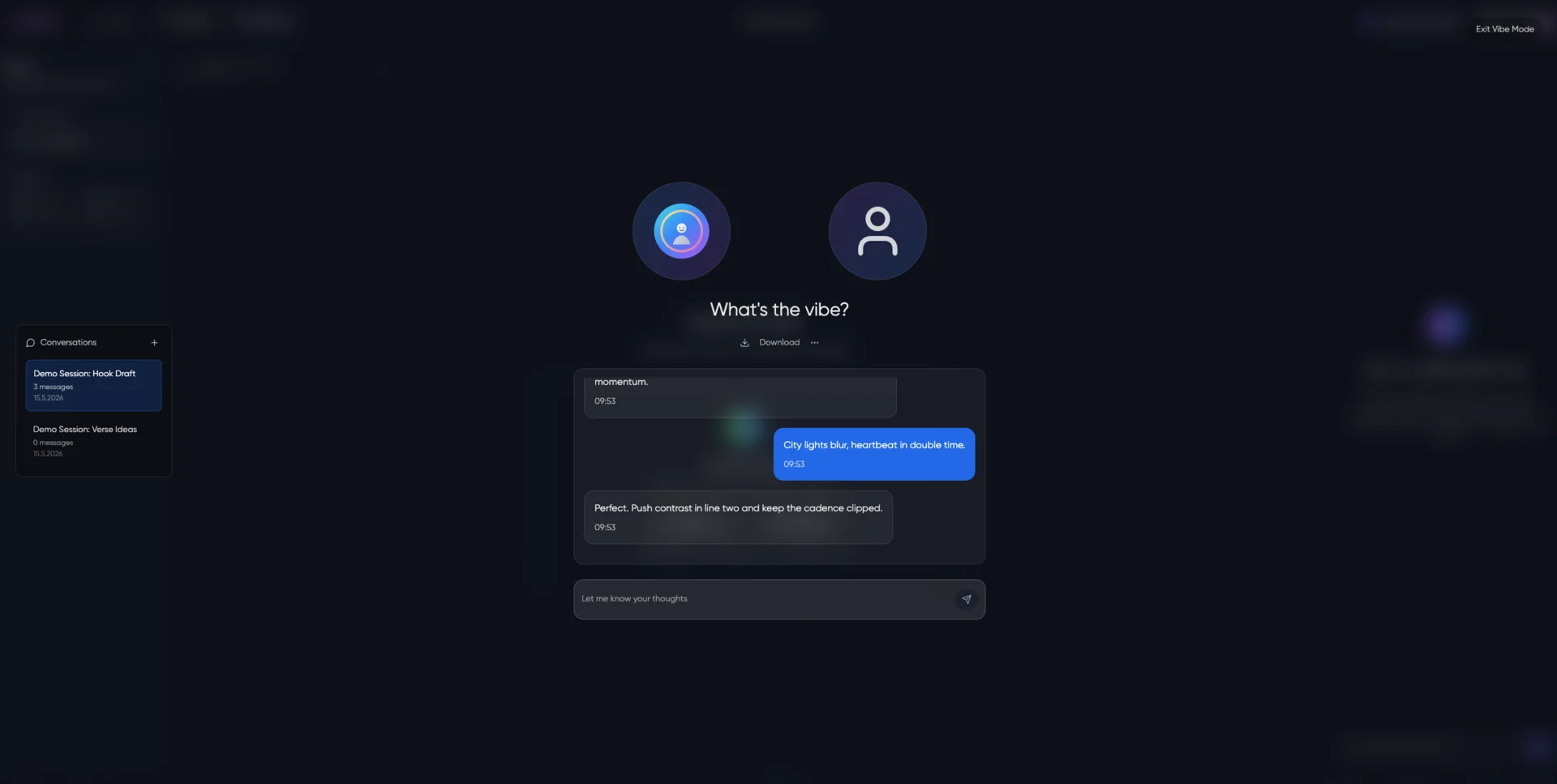
Hyperstate AI betrieb eine KI-gestützte Musikproduktionsplattform. Creator luden Audio hoch und arbeiteten mit einem produzentenähnlichen Assistenten (Louis-Bell-Persona), der den vollen Kontext über Sitzungen hinweg behielt. Dem Startup ging nach dem Launch das Funding aus.
Überblick
Hyperstate AI betrieb eine KI-gestützte Musikproduktionsplattform. Creator luden Audio hoch und arbeiteten mit einem produzentenähnlichen Assistenten (Louis-Bell-Persona), der den vollen Kontext über Sitzungen hinweg behielt. Dem Startup ging nach dem Launch das Funding aus.
Die Herausforderung
Ein einziger GPU-lastiger Server kümmerte sich um Audio-Verarbeitung, Lyrics, Transkription, MIDI-Generierung und den Producer-Agent. Deployments manuell. Die Compute-Rechnung wuchs schneller als die Nutzung. Die Architektur trug eine Demo, aber nicht den Launch – keine horizontale Skalierung, keine Fehlerisolation, ein einziger schlechter Deploy nahm das ganze Produkt offline.
Ein Server für alles würde den Launch nicht überleben.
Audio-Verarbeitung, Lyrics, Transkription, Generierung – alles auf eine GPU-Box gestapelt, händisch deployed. Hat die Demo getragen, ist unter echter Last eingebrochen. Wir haben in fokussierte Services mit klaren Verantwortungsgrenzen aufgeteilt, jede Komponente dockerisiert und die schwersten In-House-Bibliotheken durch leichtgewichtige, skalierbare Hosted-Alternativen ersetzt. Gleiche Produktoberfläche, ein Bruchteil der Compute-Rechnung, Deployments, die niemand mehr babysitten muss.
Was wir gemacht haben
GPU-lastige Integrationen aus dem monolithischen Single-Server-Setup in ein verteiltes, microservice-orientiertes Backend mit klar getrennten Verantwortlichkeiten überführt – Agenten, Audio-Verarbeitung und Generation-Services, jeweils mit eigenem Skalierungs-Profil. Den Deployment-Stack von manuellen Deploys auf eine dockerisierte, orchestrierte Infrastruktur über alle Komponenten modernisiert. Lokale, selbst verwaltete, rechenintensive Audio-, Lyrics- und Transkriptions-Bibliotheken durch leichtgewichtige, skalierbare Alternativen abgelöst – Latenz und Compute-Rechnung im selben Schritt gesenkt. Darüber: Django REST API, thirdweb-verknüpfte JWT-Auth, Projekt- und Sample-Management, MIDI-Generierungs-Workflows, Neo4j-Wissensgraph, PostgreSQL. Gleiche Produktoberfläche, eine Infrastruktur, die Wachstum trägt, statt dagegen zu kämpfen.
Ergebnisse
Was wir gelernt haben
Schwere ML-Arbeit hat im Web-Request-Path nichts verloren. Sobald Audio, Lyrics und Transkription je ein Modell in dieselbe Box ziehen, reißt jeder Lastspitze das ganze Produkt mit. Der Gewinn ist langweilige Infrastruktur: getrennte Services für getrennte Compute-Profile, orchestrierte Deploys, Hosted-Alternativen für Bibliotheken, die man nicht selbst betreiben sollte.

Wollen Sie ähnliche Ergebnisse?
Erzählen Sie uns, was Sie bauen. Wir sagen Ihnen, ob wir das richtige Team dafür sind.
Termin buchen